SPARQL 배우기
SPARQL(SPARQL Protocol And RDF Query Language)은 LOD로 구축된 데이터에 질의를 수행하기 위한 W3C의 표준 질의언어입니다. 마치 SQL을 이용하여 데이터베이스에 질의를 수행하는 것과 같이 LOD 서비스에서는 SPARQL을 이용하여 질의를 수행할 수 있습니다.
SPARQL 1.1 상세정보: http://www.w3.org/TR/sparql11-query/
SPARQL Endpoint는 웹을 통해 SPARQL을 질의할 수 있는 접근점을 의미합니다.
SPARQL Endpoint의 URL을 이용하여 질의를 작성하고 그에 해당하는 결과를 다양한 유형의 데이터 포맷으로 받을 수 있습니다.
워크넷정보 LOD 서비스의 SPARQL Endpoint는 아래의 URL을 통해 확인할 수 있습니다.
사용방법
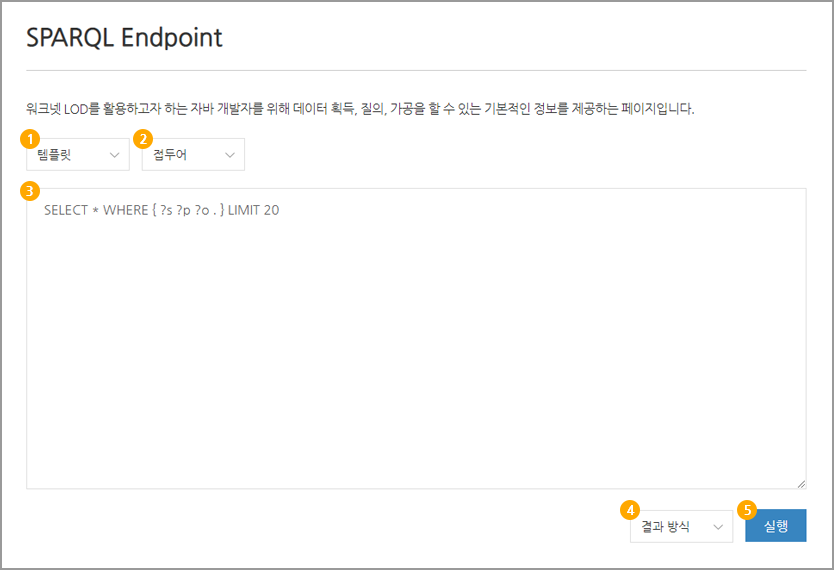
- 1SPARQL 유형을 선택할 수 있습니다.
- 2미리 정의된 Prefix를 선택할 수 있습니다.
- 3질의문을 입력하는 영역입니다.
- 4질의 결과 타입을 선택할 수 있습니다. HTML, RDF, JSON, XML, CSV 등을 입력할 수 있습니다.
- 5작성된 질의문에 대해 Submit 요청합니다.
SPARQL 질의 형식은 개략적으로 아래와 같습니다.
질의에서 사용되는 변수는 ‘?변수명’ 또는 ‘$변수명’와 같은 형태로 사용합니다.
PREFIX
SELECT / CONSTRUCT / ASK / DESCRIBE
(DISTINCT / REDUCED)
FROM (NAMED)
WHERE
Graph Pattern / OPTIONAL / FILTER / UNION / GRAPH
ORDER BY
LIMIT
OFFSET질의에서 사용되는 Prefix를 정의합니다.
사용 예PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
결과를 sort 합니다.
뒤에 sort할 변수가 오며, ASC(변수) 또는 DESC(변수)를 사용하여 정렬 순서를 정할 수 있습니다. 디폴트는 ASC이며 다중 정렬도 가능하다.
CONSTRUCT 나 DESCRIBE 에서는 Order By의 사용이 가능하지만 그 결과에는 아무런 영향을 끼치지 않습니다.
ASK 에서는 Order By 를 사용할 수 없습니다.
정렬 순서는 특정 Term들 사이에서 Fixed 되어 있습니다.
주의 : order by는 대용량 트리플의 경우 시스템 성능 저하를 초래할 수 있습니다.
Queryselect ?s ?p ?o where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s ?p ?o . } order by ?s limit 50select ?s ?p ?o where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s ?p ?o .
} order by desc(?s) limit 50결과 개수를 제한합니다.
Queryselect ?s ?p ?o where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s ?p ?o .
} limit 50 결과를 가져올 시작 번호를 정할 수 있습니다.
Queryselect ?s ?p ?o where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s ?p ?o .
} limit 5 offset 10 쿼리의 조건을 명시합니다.
Graph Pattern / OPTIONAL / FILTER / UNION / GRAPH 등을 사용하여 조건 생성이 가능합니다.
Optional은 다음과 같은 형식으로 사용 가능합니다.
- pattern OPTIONAL { pattern }
- { OPTIONAL { pattern } }
- { { } OPTIONAL { pattern } }
- pattern OPTIONAL { pattern } OPTIONAL { pattern }
- { pattern OPTIONAL { pattern } } OPTIONAL { pattern }
4번과 5번은 동일(왼쪽부터 연산됩니다.)
select distinct ?p ?o ?plabel
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s ?p ?o .
OPTIONAL
{ ?p rdfs:label ?plabel .
FILTER (lang(?plabel) = ""ko"")
}
}
limit 100공통 변수를 가지고 있지 않은 경우에는 Full Join 연산을 합니다.
Filter는 아래에 설명된 표와 같이 다양한 연산을 사용하여 조건에 대한 제한이 가능하며 이를 위해 다양한 연산방법을 제공합니다.
Queryprefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
select * where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
filter regex(?label, "직업")
} limit 50 Union 의 예제는 다음과 같습니다.
Queryprefix owl: <http://www.w3.org/2002/07/owl#>
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
select ?s ?label
where {
{ OPTIONAL{ ?s rdf:type owl:DatatypeProperty . ?s rdfs:label ?label }}
UNION
{ OPTIONAL{ ?s rdf:type owl:ObjectProperty . ?s rdfs:label ?label .} }
}변수들과 그 변수들의 값을 return 합니다.
select 뒤에는 가져올 변수를 선언해야 합니다.
여러 개의 변수들은 공백으로 구분합니다.
쿼리에서 사용된 모든 변수를 SELECT 하기 위해서 ‘*’ 문자를 사용할 수 있습니다.
SPARQL의 SELECT는 어떻게 사용하는 것일까요? 우선 데이터베이스의 SELECT문을 예로 살펴보겠습니다.
SELECT id, name
FROM author
WHERE birthYear=1933
ORDER BY id DESC
LIMIT 3
OFFSET 4위의 문장에서와 같이 질의를 하는 대상, 조건, 정렬조건, 결과건수제한 그리고 찾는 값에 대한 정보들이 있습니다.
SPARQL에서도 마찬가지로 질의하는 대상, 조건, 정렬조건, 결과건수제한 그리고 찾는 값에 대한 정보들을 SPARQL에 표현을 하게 됩니다.
먼저 자세히 알아보기 전에 기억해야 할 것은 SPARQL 쿼리는 기본적으로 트리플 패턴으로 사용자가 찾고자 하는 결과를 찾아옵니다.
트리플, 즉 주어부(subject), 술어부(predicate), 목적부(object)를 구성하는 패턴에 따라 결과를 매칭하게 됩니다.
SPARQL에서 쿼리의 유형은 제일 앞에 나오게 됩니다. 여기서는 당연히 SELECT에 대하여 설명을 하고 있으니 SELECT가 먼저 나오겠죠.
그 다음 찾는 값은 데이터베이스에서 컬럼명이 나오는데 SPARQL에서는 변수라고 지칭하는 문자를 사용합니다.
이 변수들은 특수문자인 '?' 혹은 '$'를 사용하여 표현하며 대부분은 '?'을 사용하여 표현합니다. 따라서 기본적인 모습은 'SELECT ?변수' 로 만들어집니다.
질의하는 대상은 데이터베이스에서는 FROM 절을 사용하여 표현하지만 SPARQL에서는 데이터베이스의 조건에 해당하는 WHERE를 사용하는 점이 다릅니다. 이는 위에서 설명한 트리플 패턴이라는 것으로 결과를 찾는다고 설명하였는데 여기에서 사용이 됩니다.
데이터베이스에서는 author 이라는 테이블에서 조건에 맞는 컬럼값을 가져오라는 질의이지만, SPARQL에서는 그 author 라는 정보가 트리플로 표현되어 있기 때문에 그 패턴을 WHERE절에 작성해 주는 것입니다.
그럼 여기까지 SPARQL로 표현해보면 아래와 같습니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by ?label
limit 3
offset 4각각에 대한 설명은 아래와 같습니다.
| 구분 | 설명 |
|---|---|
| SELECT | 질의 유형 |
| ?id | 찾는 변수(특수문자를 앞에 꼭 붙여야 함) |
| WHERE | 찾는 조건 입력 부분 |
| ?id | 트리플이 주어부에 해당하는 것으로 SELECT 문에서도 사용하고 있는 변수 |
| rdf:type | 트리플의 술어부에 해당하는 것으로 클래스 타입이 무엇인지를 지정함 |
| <http://lod.work.go.kr/task/업무> | 트리플의 목적부에 해당하는 것으로 업무를 가리키는 URI |
이때 WHERE에서는 { }를 사용하여 그 안에 트리플 패턴을 정의하고 있다는 것을 기억해야 합니다. 그리고 하나의 트리플 패턴이 끝날 때에는 마침표(.)를 통해 트리플이 끝났다는 것을 명시해 주어야 합니다.
이번에는 에서처럼 name을 찾는 SPARQL을 만들어보겠습니다.데이터베이스에서는 간단하게 컬럼명을 적어주면 되지만, SPARQL에서는 트리플 패턴이라고 말씀드렸듯이 WHERE절에 그 패턴을 지정해 주어야 합니다.name을 찾기 위해서는 찾는 변수 부분에 ?name을 추가하고 WHERE 절에 패턴을 추가해야 합니다.국립중앙도서관의 저자정보에는 이름을 을 사용하여 트리플을 생성하였기에
이 정보를 가지고 패턴을 만들어보면 아래와 같습니다.
SELECT ?id ?name
WHERE {
?id rdf:type <http://lod.work.go.kr/task/업무> .
?id rdfs:label ?name .
}변수는 ?name 으로 SELECT에 추가하였는데 변수들 구분하기 위해서는 공백만 있으면 됩니다. (데이터베이스처럼 콤마(,)를 통해 구분하지 않습니다)은 저자 중에서 id와 name을 찾는 쿼리입니다. 이를 좀 더 간단하게 표현할 수도 있습니다.공통된 subject를 가지는 트리플 패턴에서는 공통인 subject를 하나만 사용하고 predicate와 object를 각각 표현하며 그 구분은 세미콜론(;) 으로 합니다.
SELECT ?id ?name
WHERE {
?id rdf:type <http://lod.work.go.kr/task/업무> ;
?id rdfs:label ?name .
}는 세미콜론으로 공통된 subject를 가지는 트리플 패턴을 생성한 것이며 항상 마칠 때에는 마침표를 사용해야 합니다.
이제는 <Query 2-2>가 그 전보다 좀 간결해 졌지만 여기서 더 간결하게 생성할 수도 있습니다. <Query 2-2>를 살펴보면 < >를 사용하여 표현하는 부분이 있습니다.
이는 URI를 표현할 때 '<' 와 '>' 문자를 사용하여 그 안에 자원(Resource)이라고 하는 URI를 입력하기 때문입니다.
그런데 또 살펴보면 rdf:type 라는 것이 있습니다. 자원의 URI를 표현하기 위해서는 < > 문자를 사용하여 표현한다고 했는데 이것은 형태가 다른 부분이라고 생각할 수 있습니다만, 이는 PREFIX를 사용하여 표현한 동일하지만 다른 형태의 표현입니다.
rdf:type를 위와 같이 표현하면 <http://www.w3.org/1999/02/22-rdf-syntax-ns#t ype> 이렇게 표현이 가능합니다.
PREFIX를 사용하면 URI를 길게 쓰지 않고 짧게 사용할 수 있기 때문에 간결한 표현이 가능합니다.
그럼 PREFIX를 사용하여 <Query 2-2>를 다시 표현해면 <Query 2-3>과 같습니다.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?id ?name
WHERE {
?id rdf:type <http://lod.work.go.kr/task/업무> ;
}
이제 WHERE에서 URI를 길게 쓰지 않고 PREFIX를 사용하여 간결하게 입력할 수 있게 된 것입니다.
다른 한 가지 의문은 rdf:type는 PREFIX 선언하는 부분에 rdf가 없는데 어떻게 된 것인지 의문을 가질 수 있습니다.
이는 SPARQL를 처리하는 엔진에서 디폴트로 선언을 해주고 있기 때문에 국립중앙도서관의 SPARQL Endpoint에서는 rdf를 굳이 선언하지 않아도 내부적으로 선언을 하고 있기 때문에 별도의 선언 없이 사용할 수 있습니다.
데이터베이스에서와 마찬가지로 SPARQL에서도 특정 조건에 맞는 정보를 찾아 볼 수가 있습니다. 이때 사용하는 것이 FILTER입니다.
데이터베이스 질의에서는 WHERE 절에서 비교, 수식 등과 같은 조건을 통해 자신이 원하는 정보를 찾아오듯이 SPARQL에서는 WHERE 절 안에 FILTER를 만들어서 조건을 입력하도록 되어 있습니다. FILTER에는 다양한 연산을 사용하여 조건에 대한 제한을 사용할 수 있으며 여기에서는 심플한 것을 소개하도록 하겠습니다.
보다 다양한 연산은 3장을 참고하시기 바랍니다.
이를 적용하면 아래와 같습니다.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?id ?name
WHERE {
?id rdf:type <http://lod.work.go.kr/task/업무> .
?id rdfs:label ?name .
FILTER(STR(?name)="인력이동관리") .
}
FILTER 안에는 '('와 ')'를 사용하여 조건을 입력해야 합니다. 조건을 제한하고자 하는 변수 ?name와 그 조건을 명시함으로서 FILTER를 완성하게 됩니다.
검색한 결과에 대해서 때로는 정렬이 필요할 때가 있습니다. 이를 위해서 사용하는 것이 ORDER BY입니다. 이는 데이터베이스의 질의와 유사하게 사용됩니다. 먼저 사용되는 곳부터 살펴보면 SPARQL의 WHERE을 닫은 뒤에 ORDER BY를 사용합니다. <DBQuery> 에서와 같이 id로 정렬을 하도록 만든 SPARQL는 아래와 같습니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by ?label
정렬 순서는 디폴트로 ASC(오름차순)가 적용되어 있기 때문에 별도로 입력하지 않아도 적용이 됩니다.
하지만 역순으로 정렬을 하고자 할 경우에는 약간의 변화가 필요합니다.
ORDER BY 이후에 DESC(내림차순)을 쓰고 변수를 사용해야 합니다. 이때 변수 앞뒤로 괄호(())를 사용하여 변수를 그 안에 넣어야 합니다.
결론적으로 ASC나 DESC 모두 ORDER BY ASC(?변수) 혹은 ORDER BY DESC(?변수) 형태의 SPARQL 입니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by DESC (?label)
정렬은 하나에 대해서만 가능한 게 아니라 다중 정렬도 가능합니다. 다중 정렬을 사용하는 방법은 ORDER BY 이후에 정렬 순서에 따라 변수를 열거하여 질의를 할 수 있습니다.
이때 변수를 열거하는 경우에는 공백을 사용하여 열거하며 정렬순서를 어떤 방식으로 할 것인지에 따라 ASC나 DESC를 사용하여 변수를 열거하게 됩니다.
아래의 <Query 7>은 다중 정렬을 적용한 예시로서 첫 번째 정렬 방식은 name 오름차순으로 하고 두 번째는 id 내림차순으로 정렬을 하겠다는 의미로 사용하였습니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by ASC(?label)?name
SELECT를 사용하여 정보를 검색하다보면 예기치 않게 많은 수의 결과가 반환될 때도 있습니다.이럴 경우에 결과의 수를 제한함으로서 원하는 결과를 찾을 수 있도록 설정할 수 있습니다. 결과의 개수를 제한할 때는 LIMIT를 사용하여 매칭이 된 결과 중 사용자가 원하는 개수만큼만 가져오도록 설정을 할 수 있습니다. LIMIT가 사용되는 위치는 ORDER BY 가 끝나고 뒤에 사용하든지 ORDER BY 가 사용되지 않으면 WHERE가 끝나는 뒤에 사용하면 됩니다.<Query 8> 은 <Query 6>의 결과에 개수 제한을 걸어 10개의 결과만 가져오도록 작성한 것입니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by ?label
LIMIT 10
지금까지 조건을 만들고 정렬도 하고 개수 제한도 해보았습니다.
마지막으로는 검색한 결과를 가져올 때 몇 번째 정보부터 가져올 것인지를 정해보도록 하겠습니다.
검색한 결과가 아무런 제한이 없다면 1,000건이 있다고 가정할 때 500번째부터 10개만 가져와서 보고 싶을 경우에 사용이 가능합니다.
이때 사용하는 것이 OFFSET입니다. OFFSET을 사용하면 전체 1,000건의 정보 중에서 500번째 것부터 가져오도록 제한을 둘 수가 있습니다.
아래의 <Query 8>는 120번째부터 10개의 정보를 가져오도록 제한을 두었습니다.
select ?s ?label
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
order by ?label
limit 10
OFFSET 10
지금까지 SPARQL에서 사용하는 기본적은 것들을 살펴보았습니다. 2장에서 설명한 내용은 아주 기본적인 것들이며 대략적인 형태는 아래와 같습니다.
이 중에서 FROM(NAMED)는 약간의 혼동이 생길 수 있음으로 이 설명에서는 제외하였으며 나머지 생소한 용어는 [3장 알아두면 유용한 SPARQL]에서 자세히 다루고 있습니다.
PREFIX
SELECT / CONSTRUCT / ASK / DESCRIBE
(DISTINCT / REDUCED)
FROM (NAMED)
WHERE
Graph Pattern / OPTIONAL / FILTER / UNION / GRAPH
ORDER BY
LIMIT
OFFSET
아래의 <Query 9>는 업무라는 집합에 포함되어 있는 인스턴스의 이름을 찾는 쿼리입니다. 지금까지 사용했던 쿼리와 다른 점은 SELECT 뒤에 변수를 사용하지 않고 '*'를 사용한 점입니다. '*' 문자를 사용하면 WHERE 절에서 나오는 모든 변수를 결과로 반환할 때 사용할 수 있습니다.
select *
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?label .
}
<Query 9>의 결과는 s, label 이 한꺼번에 100건이 결과로 반환됩니다. 이 중에서 name만을 확인해보고 싶은데 사용자가 검색한 결과 중에서 중복된 결과를 제거하여 결과를 반환받고자 할 경우에 사용합니다. DISTINCT는 SELECT 뒤에 사용하며 그 다음에 중복을 제거할 변수를 사용합니다. 이를 반영한 쿼리는 <Query 10>과 같습니다.
select distinct ?name
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?name.
}
WHERE 절을 자세히 살펴보면 'a' 라는 문자가 눈에 들어옵니다. 이는 rdf:type과 같은 용도로 사용하는 것으로서 어떤 집합에 속한 것을 찾을 때 사용합니다. 2장의 쿼리들에서 사용했던 rdf:type 대신에 a로 바꾸어 사용해도 동일한 결과를 가져다줍니다. 결과적으로 <Query 10-1>과 <Query 10-2>는 동일한 쿼리입니다.
select distinct ?name
from <http://lod.work.go.kr>
where {
?s a <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?name.
}
수학에서 합집합의 개념으로 여러 가지 패턴으로 검색되는 결과들을 SPARQL에서는 합집합으로 반환받을 수 있습니다.
<Query 11>은 프로젝트 통합관리 업무와 프로젝트 저략기획 업무들을 합집합하여 결과를 달라는 의미로 사용하고 있습니다.
이 때 사용하는 것이 UNION입니다.
select *
from <http://lod.work.go.kr>
where {
{?s a <http://lod.work.go.kr/task/업무> .
?s rdfs:label "프로젝트 통합관리".}
UNION
{?s a <http://lod.work.go.kr/task/업무> .
?s rdfs:label "프로젝트 전략기획".}
}
UNION을 사용할 때에는 WHERE절과 별개로 {} 문자를 사용하여 트리플 패턴들을 묶어 줘야 합니다. 즉, WHERE { {패턴A} UNION {패턴B} } 형태입니다. UNION을 사용하지 않았을 때와의 차이점은 합집합과 교집합의 차이입니다.
다시 말하면 UNION을 사용하여 쿼리를 실행하면 이름이 고은이 사람과 1990년에 태어난 사람 모두를 결과로 반환하는 반면에 UNION을 사용하지 않고 쿼리를 실행하면 이름이 고은이면서 1990년에 태어난 사람을 결과로 반환하는 차이가 생깁니다.
WorkNet LOD에서는 공정개선이라는 업무가 존재합니다. <Query 12>는 이 경우에 사용하는 쿼리입니다.
select *
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?o .
FILTER (STR(?o) = "공정개선")
}
하지만 이 쿼리의 경우에는 공정개선이라는 업무만 반환하고, 공정개선 업무와 연결된 다른 프로퍼티의 값이 있을 때에 반환하지 않는 경우가 발생합니다. 왜냐하면 앞 절에서 설명하였듯이 교집합으로 검색을 하기 때문입니다. 이 경우에는 OPTIONAL을 사용하여 쿼리를 만들 수 있습니다.
select *
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
?s rdfs:label ?o .
FILTER (STR(?o) = "고객관리")
OPTIONAL {
?s <http://lod.work.go.kr/task/업무/핵심용어> ?coreTerm .
}
}
OPTIONAL은 데이터베이스의 Join 연산과 같은 기능을 합니다. 찾고자 하는 트리플 패턴은 {}를 사용하여 묶어주어 사용하며 여러 개의 OPTIONAL을 사용할 수도 있습니다.
<Query 13>은 고객관리 업무를 기본적으로 반환하되 그 업무의 핵심용어들이 존재하면 다 가져오라는 경우에 사용합니다.
따라서 데이터 상으로 고객관리와 그 핵심용어들이 결과로 반환되어집니다. OPTIONAL의 연산은 연산 시에 공통 변수의 여부에 따라서 연산하는 방식이 다르게 됩니다. 공통 변수라 함은 <Query 13>에서 ?s 에 해당하는 것으로 각각의 패턴에서 공통적으로 사용되는 변수를 뜻합니다. 공통 변수를 가지고 있는 경우에는 Left outer Join 연산을 수행하며, 공통 변수를 가지고 있지 않은 경우에는 Full Join 연산을 수행합니다.
지금까지 SPARQL을 통해 검색 결과를 가져오는 여러 가지 방법들에 대해서 설명하였습니다.
이번에는 검색된 결과의 개수를 알아보는 쿼리를 설명하겠습니다.
검색된 결과가 몇 건인지를 알아보기 위해서는 COUNT를 사용합니다. 이는 SELECT 뒤에 위치하며 괄호를 사용하여 변수를 묶어 사용해야 합니다. 이때 위에서 설명한 '*'를 사용해도 무방합니다.
select count(?s)
from <http://lod.work.go.kr>
where {
?s rdf:type <http://lod.work.go.kr/task/업무> .
}